Understanding Tokenization in Large Language Models
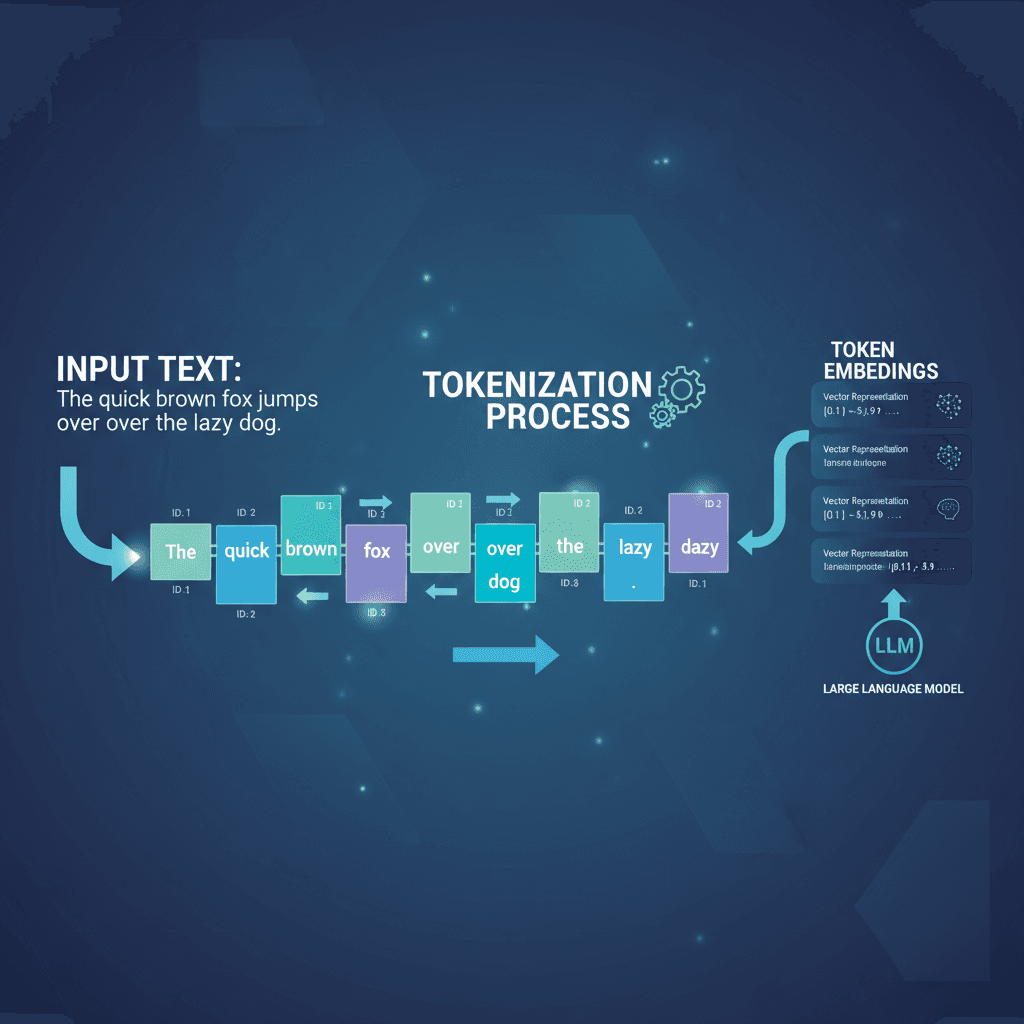
If you work with large language models (LLMs) like GPT-4, Claude, or Llama, you've probably heard the term "tokenization" before. But what exactly is it, and why should you care? In this article, we'll demystify tokenization and explain why understanding it is crucial for building efficient AI applications.
What is Tokenization?
At its core, tokenization is the process of breaking down text into smaller, manageable units called tokens. These tokens are the building blocks that language models understand and process.
Think of it like converting a sentence into words or characters, but more sophisticated. Different models use different tokenization methods, and what constitutes a "token" varies across models.
Why Does Tokenization Matter?
Understanding tokenization is essential for several reasons:
- Cost Optimization: LLM APIs charge based on tokens, not words. Knowing how text tokenizes helps you estimate and reduce costs.
- Prompt Engineering: Different ways of phrasing prompts can result in different token counts. Understanding this allows you to write more efficient prompts.
- Context Window Limits: All models have a maximum context window (usually measured in tokens). Understanding tokenization helps you stay within these limits.
- Model Comparison: Different models tokenize text differently. The same text might be 100 tokens in one model and 150 in another.
How Do Tokenizers Work?
Modern LLMs typically use a technique called Byte Pair Encoding (BPE) or variants of it. Here's a simplified explanation:
- The tokenizer is trained on a large corpus of text
- It learns common sequences of characters and creates "tokens" for them
- Common words become single tokens, while rare words are split into multiple tokens
- Special tokens are added for markers like whitespace, punctuation, or model-specific instructions
Different Models, Different Tokenizers
One important thing to remember: each model has its own tokenizer. OpenAI's GPT models use one tokenizer, Meta's Llama uses another, and so on. This means the same text will be tokenized differently depending on which model you're using.
This is why tools like Tiktokenizer are valuable – they let you visualize and compare how different models tokenize your text.
Practical Tips
💡 Quick Tips for Working with Tokens:
- Use Tiktokenizer to experiment with different prompts and see how token counts change
- Remember that spaces, punctuation, and capitalization can affect tokenization
- Common words typically tokenize to 1 token, while rare words or numbers may use multiple tokens
- Always test your prompts with the specific model you're using, as tokenization varies
Conclusion
Tokenization might seem like a technical detail, but it's fundamental to understanding how language models work. By understanding how your text is tokenized, you can write more efficient prompts, better estimate API costs, and build more effective AI applications.
Ready to explore tokenization? Head over to our interactive tool to see how different models tokenize your text!
Try It Yourself
Want to see tokenization in action? Use Tiktokenizer to visualize how different models tokenize your text.
Go to Tokenizer