RAG Systems and Tokenization: Building Efficient Retrieval-Augmented Generation
Retrieval-Augmented Generation (RAG) is revolutionizing how we build AI applications that leverage proprietary knowledge bases. However, RAG systems introduce unique tokenization challenges. This guide explores how to optimize RAG architectures for both performance and cost using tokenization insights.
What is RAG and Why Tokenization Matters
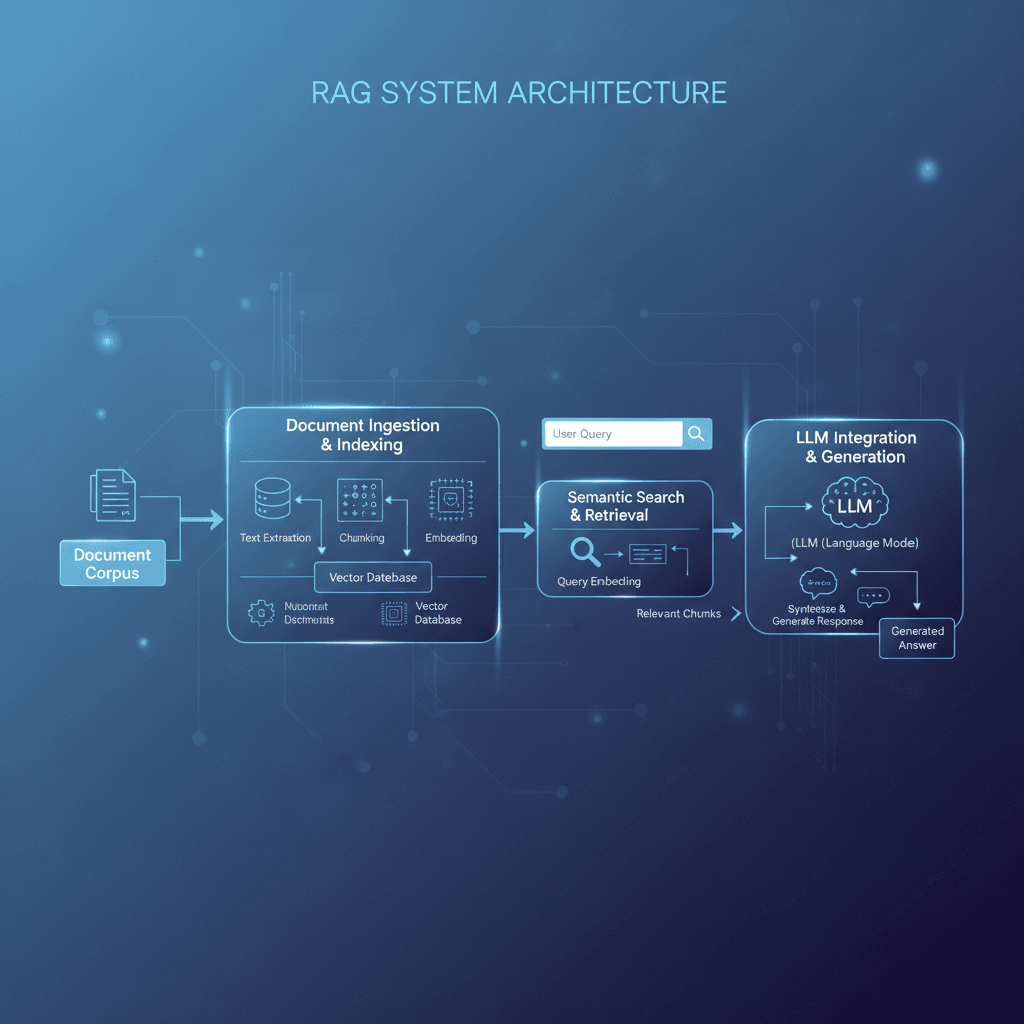
RAG combines semantic search with language models:
- User submits query
- Retrieve relevant documents from knowledge base
- Augment LLM prompt with retrieved context
- Generate response using both retrieved context and user query
Tokenization impact: Retrieved documents add to your token count. A 10-document retrieval with 500 tokens each means 5,000 tokens of context per request.
Key RAG Architecture Decisions
1. Chunk Size Selection
How you split documents into chunks dramatically affects tokenization:
Small chunks (256 tokens):
+ More granular retrieval accuracy
+ Better context relevance
- More chunks to store
- Potential context fragmentation
Large chunks (1024 tokens):
+ Complete context in single chunk
+ Fewer retrieval calls
- Risk of irrelevant content
- Higher token cost per retrieval
Recommendation: Start with 512-token chunks. Use Tiktokenizer to ensure consistency across different content types.
2. Number of Retrieved Documents
Balance retrieval quality with token costs:
Scenario: 5 documents × 500 tokens each
Using GPT-4o: 2,500 tokens × $5/1M = $0.0125 per request
10,000 daily requests = $125/day cost from context alone!
Using 3 documents: $75/day
Using 8 documents: $200/day
Optimization tip: Start with 3-5 documents. Monitor accuracy vs. cost trade-off.
3. Hybrid Retrieval Strategies
Don't retrieve blindly. Smart retrieval reduces token waste:
- Semantic search: Use embeddings for relevance scoring
- BM25 (keyword matching): Quick filtering before semantic scoring
- Multi-stage ranking: Retrieve 20, rerank to 5 most relevant
- Query expansion: Rephrase query to catch more documents
- Metadata filtering: Pre-filter by date, category, etc.
Tokenization-Aware RAG Strategies
Strategy 1: Dynamic Context Windows
Allocate context space based on content importance:
Example with 4K token budget:
System prompt + Instructions: 500 tokens (fixed)
User query: 100 tokens (variable)
Retrieved context: X tokens (optimize here)
Response buffer: 500 tokens (reserved)
Available for retrieval: 4000 - 500 - 100 - 500 = 2900 tokens
Max documents: 5-6 depending on size
Strategy 2: Summarization-Enhanced RAG
Pre-summarize documents before retrieval:
- Create 2-3 sentence summaries of each chunk
- Use summaries for semantic search
- Retrieve only when summary matches query
- Reduces token cost by 30-50%
Cost comparison:
Standard RAG: 2,500 tokens/request × $5/1M = $0.0125
Summarization RAG: 1,500 tokens/request × $5/1M = $0.0075 (40% savings)
Strategy 3: Token-Aware Chunk Overlap
When chunking documents, consider overlap:
- No overlap: Faster chunking, risk of context loss at boundaries
- 20% overlap: 100 tokens overlap on 500-token chunks - smooth transitions
- 50% overlap: Safer but doubles storage and retrieval complexity
Recommendation: Use 20% overlap. Use Tiktokenizer to calculate exact overlap in tokens.
Implementation Best Practices
1. Embedding Model Alignment
Your embedding model should match your LLM:
- OpenAI (text-embedding-3): Matches tokenization of GPT models
- Sentence Transformers: Uses different tokenization - may need adjustment
- Custom embeddings: Train on same data as retrieval corpus
2. Prompt Engineering for Retrieved Context
Structure your RAG prompt efficiently:
System: You are a helpful assistant.
Retrieved Documents:
[Doc 1 title and summary - 50 tokens]
[Doc 2 title and summary - 50 tokens]
[Doc 3 content - 400 tokens]
User: [Query]
Include summaries of non-primary documents to reduce token waste.
3. Fallback Strategies
Handle cases where retrieval fails or returns poor results:
- No results: Use general knowledge without retrieval context
- Low confidence: Use fewer documents and rely on LLM knowledge
- High token consumption: Re-rank and reduce document count
- Slow retrieval: Implement caching for common queries
Measuring RAG Efficiency
Track these metrics for your RAG system:
- Context relevance: Are retrieved documents actually relevant? (manual evaluation)
- Tokens per request: Monitor token consumption growth
- Cost per request: Track actual API costs
- Retrieval latency: Time to fetch and rank documents
- Generation quality: Does RAG improve answer quality? (benchmark against no-RAG)
Cost Optimization Example
Scenario: Customer support chatbot with 50K daily requests
Initial implementation:
- 6 retrieved documents × 500 tokens = 3,000 tokens context
- System prompt: 500 tokens
- Total: 3,500 tokens input per request
- Using GPT-4o: 3,500 × 50K × $5/1M = $875/day
Optimized implementation:
- 3 retrieved documents × 300 tokens (chunked better) = 900 tokens
- Compressed system prompt: 250 tokens
- Total: 1,150 tokens input per request
- Cost: 1,150 × 50K × $5/1M = $288/day
Savings: 67% reduction ($587/day saved!)
Advanced: Adaptive RAG
For sophisticated systems, implement adaptive RAG:
- Query classification: Determine if RAG needed
- Dynamic retrieval: Adjust document count based on query complexity
- Reranking: Use cross-encoder to score documents
- Cost-aware routing: Route to cheaper models when possible
Conclusion
RAG systems are powerful but require careful optimization to manage token costs. By implementing smart chunking, dynamic retrieval, summarization, and monitoring token usage, you can build RAG applications that are both accurate and cost-effective.
Use Tiktokenizer throughout your RAG pipeline: to size chunks, estimate costs, optimize prompts, and analyze retrieved content. The insights will help you build RAG systems that scale sustainably.